本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下: 一、背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很...
”python 爬虫框架 scrapy 模拟登录“ 的搜索结果
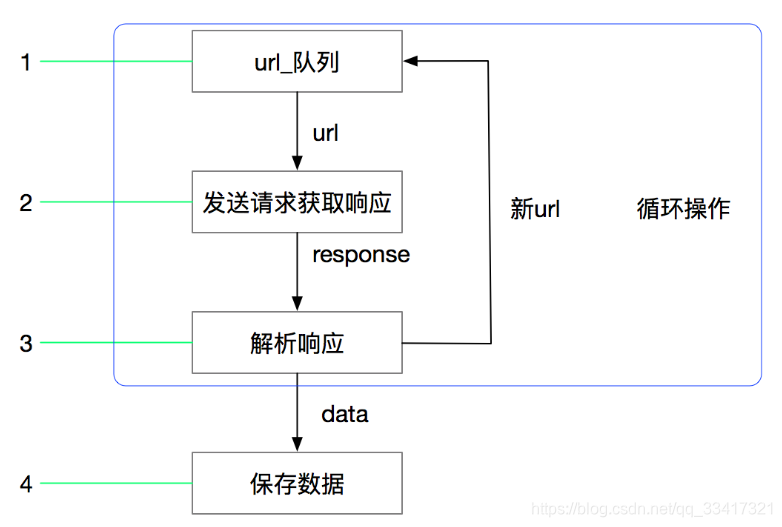
目标: 应用 请求对象cookies参数的使用 了解 start_requests函数的作用 应用 构造并发送post请求
文章目录模拟登录(一)网站登录实质(二)发送 Post 请求模拟登录1. 使用 FormRequest2. 实现登录 Spider(三)携带 Cookies 模拟登录1. 人工获取 Cookie 模拟登录(1)人工获取 Cookie(2)模拟登录知乎2. ...
本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下:一、背景:初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很多...
展开全部开发网络爬虫32313133353236313431303231363533e78988e69d8331333339663330应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?这里按照我的经验随便扯淡一下:上面说的爬虫,基本可以分...
本文是本人在b站上学习尚硅谷的Python爬虫教程小白零基础速通的,关于爬虫部分后记录的笔记。
3. Scrapy:一个高级的Web爬虫框架,提供了强大的爬取和数据提取功能。 4. Selenium:用于模拟浏览器行为,支持动态网页的爬取。 5. PyQuery:类似于jQuery的语法,用于解析HTML文档。 6. lxml:基于C的高性能...
九、Scrapy模拟登录人人网 作者:Irain QQ:2573396010 微信:18802080892 视频资源链接:Scrapy模拟登录人人网. 1 创建scrapy项目和爬虫 参考链接:在DOC窗口创建scrapy项目和爬虫. 2 settings.py设置 参考...
Python爬虫简介 网络爬虫在当今信息化社会中扮演着重要角色,帮助我们从互联网上获取各种数据。Python作为一种简单易学且功能强大的编程语言,在爬虫领域有着广泛的应用。 ## 1.1 什么是网络爬虫? 网络爬虫...
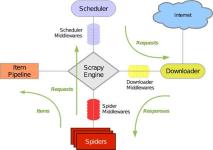
Scrapy 是一个用于爬取网站数据的强大的开源 Python 框架。它提供了一个高级的抓取和数据提取工具集,使您能够快速、灵活地构建和扩展网络爬虫。强大的功能:Scrapy 提供了一套完整的工具和功能,包括请求调度、数据...
Scrapy是基于Python的网络爬虫框架,它提供了一套强大的工具和框架,使得爬取网页数据变得简单高效。其优势包括但不限于: - 快速高效:异步处理和并发控制带来高效的爬取速度 - 灵活性:支持定制化的定位、解析和...
Scrapy是一个用Python编写的开源网络爬虫框架。
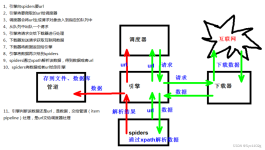
日志打印1、 日志信息2、 logging 模块四、 全站爬取1、 使用request排序入队2、 继承crawlspider五、 二进制文件1、 图片下载六、 middlewares1、下载中间件2、 爬虫中间件七、 模拟登录1、 cookie2、 直接登录八、

scrapy模拟登陆 学习目标: 应用 请求对象cookies参数的使用 了解 start_requests函数的作用 应用 构造并发送post请求 1. 回顾之前的模拟登陆的方法 1.1 requests模块是如何实现模拟登陆的? 直接携带cookies...
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML...这不说验证码的事儿,你可以自己手动输入验证,或者直接用云打码平台,这里我们介绍一个scrapy的登录用法。 测试登录地址:http://example.w

遵守规则: 为避免对网站造成过大负担或触发反爬虫机制,爬虫需要遵守网站的robots.txt协议,限制访问频率和深度,并模拟人类访问行为,如设置User-Agent。 反爬虫应对: 由于爬虫的存在,一些网站采取了反爬虫措施...

scrapy爬虫框架课程,包含全部课件与代码 课程纲要: 1.scrapy的概念作用和工作流程 2.scrapy的入门使用 3.scrapy构造并发送请求 4.scrapy模拟登陆 5.scrapy管道的使用 6.scrapy中间件的使用 7.scrapy_redis概念作用...
scrapy_splash是scrapy的一个组件scrapy-splash加载js数据是基于Splash来实现的。Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块...
scrapy_redis是scrapy框架的基于redis的分布式组件 (3)scrapy_redis的作用 Scrapy_redis在scrapy的基础上实现了更多更强大的功能,具体体现在: 通过持久化请求队列和请求的指纹集合来实现: 断点续爬 ...
Scrapy框架具有以下特点:易用性、灵活性、可扩展性、速度快、易维护等。它提供了丰富的中间件和插件,支持各种数据抓取任务,并可轻松地与其他库集成。在爬虫文件中定义请求规则和中间件,以实现数据的抓取任务。...
导语:网络爬虫是一种重要的数据...本文将详细介绍两个知名的Python网络爬虫框架:Scrapy和PySpider。我们将分别探讨它们的特点、用法以及示例代码,帮助你选择适合的框架来开发高效的网络爬虫。一、Scrapy框架简介。
dada
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地